Preview
Designed for simplicity. Built for power.
A clean, focused interface that gets out of your way.

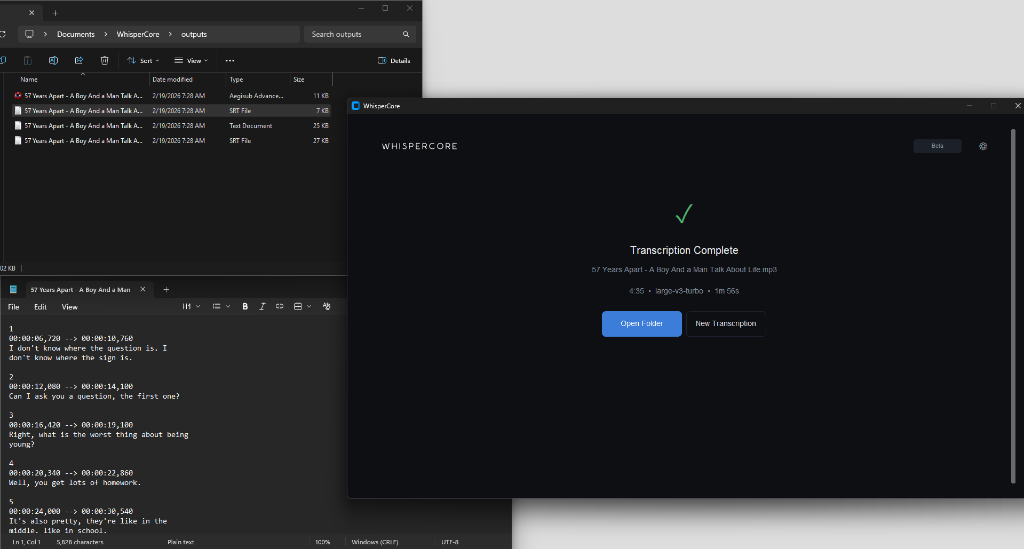
Active State
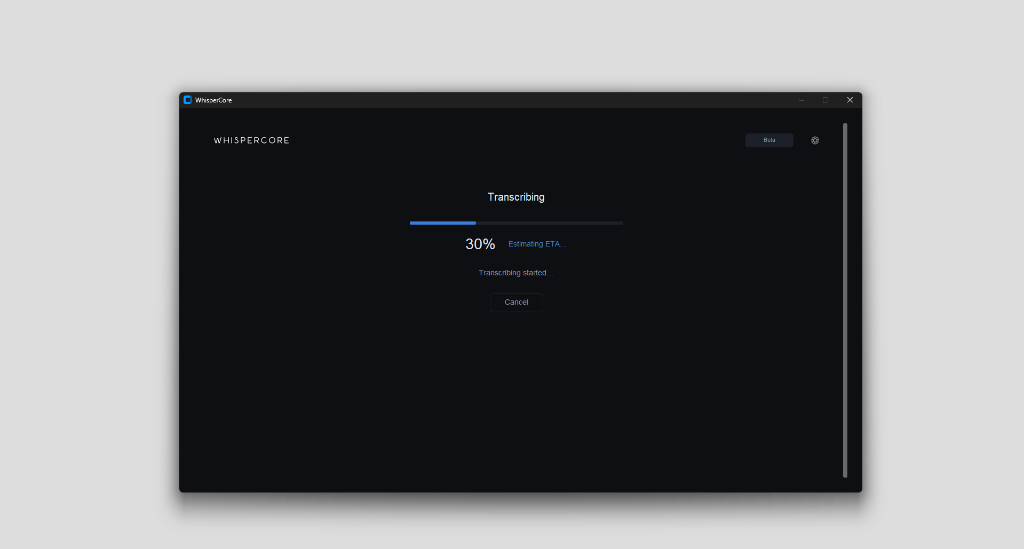
Result View